
La randomisation ou comment créer une contrefactuelle
Le principe de l’évaluation d’impact est de mettre en évidence l’effet causal – qu’Esther Duflo définit dans L’approche expérimentale en économie du développement [ref] comme « la différence entre la situation dans laquelle [un agent] se trouve lorsqu’il a bénéficié du programme et celle dans laquelle il se trouverait s’il n’en avait pas bénéficié » – d’un programme donné sur un échantillon restreint d’une population. Estimer un tel impact nécessite donc de connaître le contrefactuel, c’est-à-dire ce qui se serait produit en l’absence d’intervention. Si l’échantillon est restreint à un individu, il est impossible d’avoir accès au contrefactuel : c’est le problème dit de l’inférence causale, que décrit James Heckman dans l’article Randomization and social policy evaluation [ref] qu’il publie en 1992 :
« A crucial feature in the evaluation program is that we do not observe a same person in both states. »
Partant de ce constat qu’« il est bien entendu impossible d’identifier les effets du traitement pour chaque personne individuellement », Ester Duflo [2009] propose de mesurer l’effet causal moyen du programme. Pour ce faire, on procède à une évaluation simultanée sur deux groupes, l’un dit traité, qui participe au programme et l’autre dit témoin (que l’on appelle également le contrefactuel), qui n’y participe pas. Selon Esther Duflo [2009], « l’expérience randomisée, en faisant varier un seul facteur à la fois (le programme), nous permet d’obtenir une estimation valide de l’effet moyen d’un traitement pour une population donnée ».
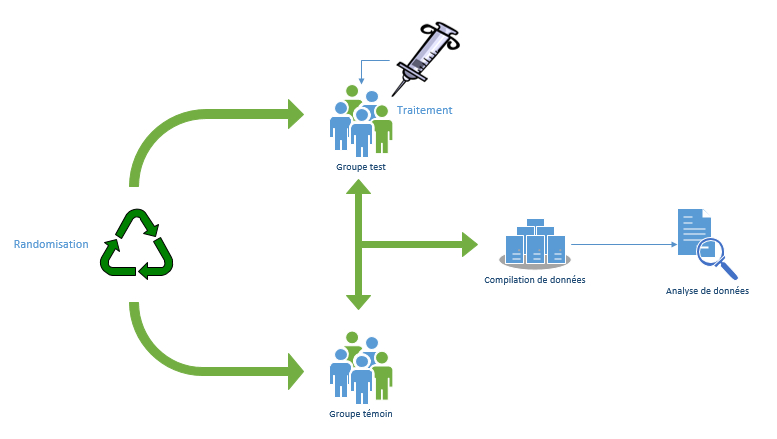 Protocole expérimental d’un RCT
Protocole expérimental d’un RCT
Le choix des groupes traité et témoin est primordial pour la validité des résultats de l’expérience. Ces groupes doivent être à la fois les plus identiques possible, pour que le contrefactuel soit pertinent, et également les plus représentatifs de la population générale, pour que les résultats présentent de l’intérêt. Afin de réduire au maximum les différences initiales entre les deux groupes étudiés, auquel cas se présente un biais dit de sélection dans les résultats, le choix des échantillons se fait de manière aléatoire : c’est la randomisation. Dans son livre Les expérimentations aléatoires en économie[ref], le normalien agrégé de sciences économiques et sociales Arthur Jatteau explique que ce tirage au sort aboutit à ce que les deux groupes « soient « comparables », suivant un certains nombres de variables, non seulement observables […] mais aussi, et c’est toute la force de la méthode, non observables ».
L’intérêt de l’idée de la randomisation est reconnu par la plupart des acteurs y compris ceux qui maintiennent une position relativement critique envers les résultats des RCT. James Heckman [1992] décrit cet argument de randomisation comme étant « simple et convainquant ». Pour Yannick L’Horty et Pascale Petit dans Évaluation aléatoire et expérimentations sociales[ref], cette méthode permet effectivement de « s’affranchir de ces bais de sélection » et de « produire un chiffrage très robuste avec une grande économie de moyen statistique ou économétrique ». Enfin, le chercheur que nous avons interrogé et qui a souhaité rester anonyme[ref] partage le sentiment que l’ « idée de départ peut être tout à fait louable » et que cette « motivation est très bonne à la base ».
Cependant, la confrontation de ce protocole aux réalités du terrain se traduit par l’apparition d’effets divers qui menacent la validité des résultats obtenus et rendent sceptiques de nombreux acteurs quant à la pertinence des RCT.