
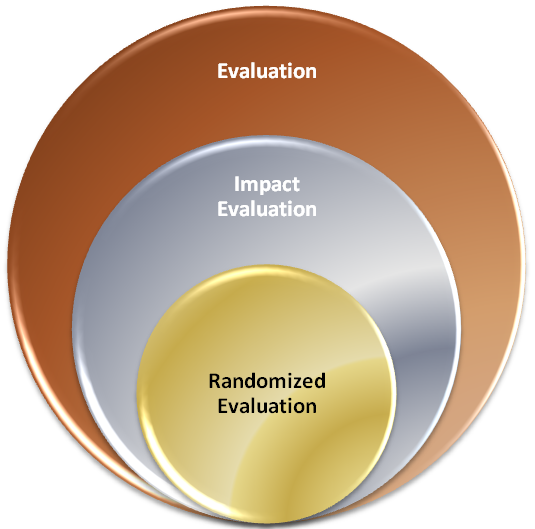
 Vue du J-PAL sur la place des évaluations randomisées dans l’évaluation (source : site du J-PAL)
Vue du J-PAL sur la place des évaluations randomisées dans l’évaluation (source : site du J-PAL)
Selon le site du J-PAL, « l’évaluation de programme » regroupe l’ensemble des moyens mis en œuvre pour évaluer « les politiques et programmes sociaux visant à améliorer les conditions de vie des personnes pauvres partout dans le monde ». La question centrale à laquelle doit répondre l’évaluation est alors celle de l’ « efficacité » du programme – cette efficacité étant comprise au sens large.
Dans la famille très large de l’évaluation, l’évaluation d’impact cherche à déterminer l’impact d’un programme – c’est-à-dire l’effet de son application, estimé à partir de différentes données propres au programme étudié – « et surtout de quantifier cet impact ». Obtenir une estimation de cette impact nécessite, comme on a pu le préciser dans la partie Mesurer un effet, de se poser la question de ce qu’il se serait passé en l’absence d’intervention : on parle de contrefactuel. Pour répondre à cette question, le principe est de « créer » une contrefactuelle, c’est-à-dire de s’intéresser à « un groupe de personnes qui n’ont pas pris part au programme mais qui ressemblent beaucoup aux participants, et plus exactement aux participants s’ils n’avaient pas bénéficié du programme », comme le rapporte le site du J-PAL. Finalement, l’efficacité d’un programme est estimé à partir de la comparaison des résultats du groupe ayant participé et avec ceux du groupe n’ayant pas participé.
La création du groupe de comparaison est une étape cruciale dont dépend en grande partie la validité des résultats obtenus. Un certain nombre de méthodes existent pour faire l’évaluation d’impact. Elles diffèrent par la manière dont est choisi le groupe de comparaison et par la façon dont on fait la comparaison entre les deux groupes étudiés. Le site du J-PAL les regroupent dans un tableau.
On y trouve notamment les méthodes suivantes :
• « Pre-post » : consiste à mesurer l’évolution des personnes participant au programme.
• « Differences in differences » (« diff in diff »): consiste à comparer l’évolution des personnes ayant participé à celle des personnes n’ayant pas participé – ce deuxième groupe n’étant pas choisi identique statistiquement au premier.
• « Statistical matching » : consiste à sélectionner pour chaque personne du groupe participant au programme une personne n’y participant pas, identique du point de vue de différents critères dépendant du programme. On compare ensuite les deux groupes.
Les chercheurs du J-PAL ont choisi la méthode de l’évaluation randomisée. Cette méthode, que nous écrivons plus précisément dans la partie La contrefactuelle, consiste à procéder à la répartition des individus dans les groupes de test et de contrôle de manière aléatoire.
Le site du J-PAL affirme sans ambages que, parmi les différentes méthodes, « les évaluations aléatoires sont les plus performantes » dans l’optique de créer une bonne contrefactuelle. Par ailleurs, le choix des chercheurs affiliés au J-PAl de se concentrer sur des évaluations aléatoires est renforcé par le sentiment qu’ils ont que si les « autres méthodes ne donnent pas toujours la mauvaise réponse, […] elles reposent plus sur des hypothèses ». Hypothèses dont il est « généralement impossible et toujours laborieux [d’assurer] l’exactitude », selon ce qui est expliqué sur le site des tenants des évaluations randomisées. Au contraire, les chercheurs du J-PAL sont confiants dans le fait que les évaluations aléatoires échappent « aux débats houleux sur les hypothèses » – affirmation toutefois discutée par de nombreux acteurs.
Les chercheurs du J-PAL placent donc une confiance très forte dans les potentialités de leur méthode et vont jusqu’à partir du principe qu’elle supplante l’ensemble des autres méthodes d’évaluation d’impact. Le parti pris du tableau qui va jusqu’à classer l’évaluation aléatoire dans la catégorie « Méthode expérimentale » tandis que toutes les autres méthodes sont regroupées dans la catégorie « Méthodes quasi-expérimentales » est un bon exemple de l’apparent dénigrement voué aux autres méthodes.
Partant de ces différentes considérations, les tenants des évaluations aléatoires considèrent, à l’instar d’Ilf Bencheikh[ref] Directeur-Adjoint au J-PAL Europe, que contrairement aux RCT pour lesquelles « on est très sûr des résultats dans l’expérimentation », « pour les autres méthodes, « avant/après », « matching », « diff and diff », on n’est jamais complètement sûr de la validité interne » – c’est-à-dire la force du lien de causalité entre le programme et l’effet observé – « et on doit ainsi prendre d’autant plus de pincettes pour la validité externe » – c’est-à-dire la capacité à tirer des conclusions plus générales du résultats de l’évaluation.
Le site du J-PAL conclut que « les autres méthodes fournissent souvent des résultats trompeurs, lesquels entraînent les responsables politiques à prendre des décisions erronées ».